Scalable Semantic Matching: Leveraging FAISS, nmslib, and Elasticsearch for Efficient Query Processing
Introduction
We recently tackled a challenge involving the identification of relevant entries based on semantic matching. The goal was to create a system capable of matching user queries with entries in a master database, which contains various attributes and data points. This is crucial as it helps users find the most relevant information, ensuring they have access to the latest insights and features.
Users can submit their queries in bulk as streams, and expect these queries to be matched with the corresponding entries in the database. The system must handle a large volume of queries efficiently, providing accurate results even as the master database continues to grow and evolve.
During the development of our solution, we had to consider several scenarios:
- What happens if a query does not exist in the master database?
- How do we handle cases where a matching entry is found, but certain attributes do not match?
- What if the database contains results that are similar but do not exactly match?
In addressing these challenges, we implemented a robust architecture that leverages advanced search technologies. Let’s explore how we approached this problem and the technologies we utilized.
More about Master Data …
The master data consists of over 343,000 entries, each containing relevant information about various products and their attributes. Each product can have multiple entries based on different attributes, such as release dates, support status, and other key indicators. Some products may currently be supported, meaning they do not have an end-of-life (EOL) date listed, while others have specific support dates indicating when they will no longer receive support.
Test Case Scenario:
Input Queries:
A batch of user queries is submitted, containing product names and their associated attributes. For example:
| Query Number | Query |
| 1 | Product A v1.0 |
| 2 | Product B |
| 3 | Product C v2.1 |
| 4 | Product D |
| 5 | Product E v3.0 |
Master Data Entries:
The master data contains the following entries:
| Entry Number | Product | Support Date |
| 1 | Product A v1.0 | 2023-12-31 |
| 2 | Product A v1.1 | 2024-06-30 |
| 3 | Product B | None (Currently Supported) |
| 4 | Product C v2.0 | 2025-01-15 |
| 5 | Product C v2.1 | None (Currently Supported) |
| 6 | Product D v1.0 | 2022-11-30 |
| 7 | Product E v3.0 | 2024-03-15 |
| 8 | Product F v1.0 | 2023-09-30 |
Expected Output:
Based on the input queries, the system should return the following matches:
| Query Number | Query | Matched Product | Support Date |
| 1 | Product A v1.0 | Product A v1.0 | 2023-12-31 |
| 2 | Product B | Product B | None (Currently Supported) |
| 3 | Product C v2.1 | Product C v2.1 | None (Currently Supported) |
| 4 | Product D | Product D v1.0 | 2022-11-30 |
| 5 | Product E v3.0 | Product E v3.0 | 2024-03-15 |
Handling Edge Cases:
- If a query does not match any entry in the master data, the system should return a message indicating no match was found.
- If there are similar entries without exact matches, the system should return the closest match based on semantic similarity.
Performance Metrics:
- The system should handle the batch of queries efficiently, providing results within a specified time frame (e.g., under 2 seconds for 1000 queries).
- Accuracy of the matches should be monitored to ensure that users receive the most relevant results.
This test case illustrates how the semantic matching system can effectively process a large volume of queries against a comprehensive master data set, ensuring accurate and timely responses.
Approach and Query Format
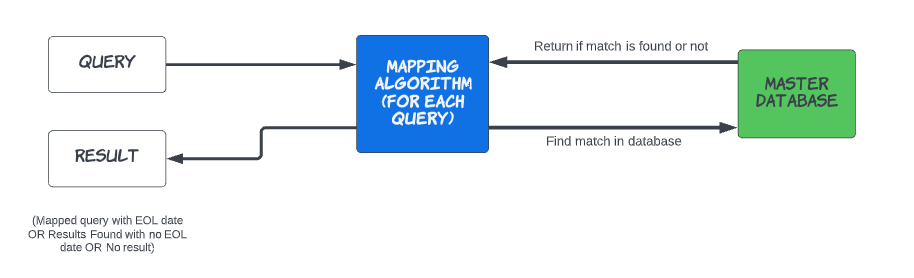
We had two methods for framing our queries:
- Combined Format: The first approach involved using a single string that combines the identifier and its associated attribute (e.g., identifier + ” ” + attribute). We explored methods like FAISS and nmslib (HNSW) that create an index using the master data. These indexes are built on the vector representation of strings, utilizing KNN (K-Nearest Neighbors) and ANN (Approximate Nearest Neighbors) algorithms to obtain optimal results by calculating the minimal distance between vectors. Establishing these indexes requires significant time and resources, particularly in terms of memory. Therefore, creating indexes that include both identifiers and their attributes is highly advantageous. To query against this index, the input must be formatted in the same way, making the combined string format a suitable option.
- Separate Fields: The second approach involves employing keyword matching techniques, such as those provided by Elasticsearch. These methods generate an index with multiple fields that can be queried similarly to a relational database. This allows for searching by identifiers and attributes as separate fields without incurring additional resource costs. By narrowing down the results, we can first search for the identifier and then refine the search for attribute matches.
Examples of Identifiers and Attributes
| Identifier | Attribute |
| Product A | Support Date |
| Product B | Release Date |
| Application X | Status |
| Tool Y | Version |
| Library Z | Compatibility |
Scoring
Each algorithm employs a distinct scoring system for the results. For instance, Elasticsearch (which is keyword-based) utilizes Lucene’s TF-IDF scores, while FAISS and nmslib (which are vector-based) rely on cosine similarity scores, which measure the angle between two vectors. These scores are instrumental in establishing a cutoff to filter out poor results.
Accuracy
To evaluate accuracy, we selected 1,000 queries with defined support dates and used them as GOLD DATA to calculate the accuracy using F1 scores.
Matching Strategy
When matching, we prioritize identifiers by aligning them with the parent entry or main record if an exact match is not found. Major and minor attributes are given precedence, as most sources provide support dates for major.minor attributes, encompassing all builds and patches under that umbrella.
If there is no exact attribute match, we then look for a higher attribute by focusing on the major and minor values.
This structured approach ensures that our system can effectively handle a variety of query formats and provide accurate, relevant results based on the master data.
What we tried? And How?
We explored various algorithms and methods to address this challenge, each with its own advantages and drawbacks. Let’s review them:
Fuzzy Search
Our initial solution involved using Fuzzy Search algorithms to calculate the number of operations required to convert one string to another. The fewer the number of operations, the more similar the strings are. However, performing these string operations at scale proved to be very costly, taking 2-3 minutes to process a single query. This was not the desired performance.
Inverted Index
Inverted indexing is a technique that tokenizes a sentence and creates a dictionary, mapping each word to the IDs where that token appears. When querying, we search for keywords in this dictionary and return the IDs of results where those keywords are found.
Ex.,
# Adobe Acrobat Reader (Identifier)
{
"adobe": [ids],
"acrobat": [ids],
"reader": [ids], ...
}
# 10.2.3.5 (Attribute)
{
'10': [ids],
'10.2': [ids],
'10.2.3.5': [ids], ...
}
We explored various algorithms and methods to address this challenge, each with its own advantages and drawbacks. Let’s review them:
We indexed the identifiers and attributes from the master data using this approach. It significantly improved performance, allowing us to process all 1,000 queries in just 20 seconds. This was possible because dictionary lookups in Python are very fast. This method works on the principle that “the more words match, the more similar the strings are,” which is not always the case. As a result, the accuracy was not satisfactory.
To enhance the results, we selected a few top matches based on the number of matches and applied fuzzy matching to re-rank them. However, this did not provide a substantial improvement.
These approaches demonstrate the trade-offs between performance and accuracy when dealing with approximate string matching at scale. While inverted indexing offered significant performance gains, it sacrificed accuracy compared to more sophisticated fuzzy matching algorithms. Combining multiple techniques can help strike a balance, but finding the optimal solution requires careful consideration of the specific requirements and constraints of the problem at hand.
| # Queries | Execution Time |
| 10 | 426 ms |
| 100 | 2.81 s |
| 500 | 14.6 s |
| 1000 | 20 s |
(Execution time for different batches of data)
In our quest for improvement, we explored various industry-standard methods and algorithms available in the field. This exploration led us to discover several promising options, and we began measuring their accuracy to assess their effectiveness.
Elastic Search
When it comes to faster searches, elasticsearch is often the first tool that comes to mind. By default, Elasticsearch employs keyword matching for its queries. It operates on a bag-of-words NLP model, which essentially creates a JSON object that captures which words frequently co-occur by analyzing a collection of sentences. Internally, it utilizes an inverted index with additional enhancements, returning the smallest results first. We can further refine the scoring by assigning weightages to specific field matches.
# Query Format
“query”: {
“function_score”: {
“query”: {
“bool”: {
# Example: 10.2.3.5 (Identifier)
“should”: [{ “match”: { “attribute”: ATTRIBUTE } }],
“must”: [
{
“wildcard”: {
“attribute”: {
“wildcard”: MAJOR.MINOR_ATTRIBUTE # e.g., 10.2*
}
}
},
{
“match”: {
“identifier”: { “query”: IDENTIFIER } # Main Identifier
}
}
]
}
},
“min_score”: THRESHOLD
}
}
MAJOR.MINOR_ATTRIBUTE: This must match the major.minor attribute. If there is an exact match for the attribute, that entry should be prioritized.
Elasticsearch offers various methods for matching, including BM25 and LM Dirichlet.
| Method | Querying Time (1000 Queries) | F1 Score |
| ES BM25 | 2.81 s | 0.89 |
| ES LM Dirichlet | 2.64 s | 0.89 |
Whoa! That is fast! Accuracy is good as well. But there are some problems.
- Since Elasticsearch is a keyword based matching algorithm, it will try to match results if more words match.
- Elasticsearch is not very good at handling punctuations. Ex., (nodejs != node.js)
- If there are no results matching the search params, it will not return a result. But in such cases, we want the nearest match with a higher version.
Vectorized Similarity Search
To address the challenges we encountered, we explored vector-based similarity matching approaches using nmslib and FAISS. These methods require a vector representation of strings to create a searchable index. In our case, the strings were formatted as a single entry combining the identifier and its associated attribute (e.g., identifier + ” ” + attribute) from the master data.

For encoding these strings, we utilized sentence-transformers, a popular collection of NLP models. These models are trained on a vast number of sentences and can encode them into semantic vectors. This means that two strings with similar contexts will have comparable vectors, which is precisely what we aimed for. We employed the all-mpnet-base-v2 model, which provides high-quality encodings with a vector dimension of 768. Given the computational intensity of this task, using a GPU is recommended.
nmslib
nmslib is a fast similarity search algorithm that primarily operates using the HNSW method. As a vector-based search algorithm, we created an index using the vector representations of the combined strings (identifier + ” ” + attribute) from the master data.
| Indexing Time | Querying Time (1000 Queries) | F1 Score |
| 1 min 15 sec | 240 ms | 0.63 |
The query time is quite fast; however, the accuracy is only 0.63, which is significantly lower than what we achieved with Elasticsearch. This represents a downgrade in performance.
FAISS
FAISS is an AI-based similarity search algorithm developed by Facebook (now Meta). It also uses vectorized strings to create the index. There are various methods available for creating this index, such as FlatIndex and IVFFlatIndex. We tested both options and ultimately decided to proceed with IVFFlatIndex.
| Index Method | Indexing Time | Querying Time (1000) | F1 Score |
| FAISS Flat Index | 1.71 s | 25 s | 0.91 |
| FAISS IVF Index | 1.92 s | 16 s | 0.91 |
The F1 score is impressive, showcasing the effectiveness of Facebook’s implementation. However, the query time is considerably higher compared to other approaches we evaluated earlier. Fortunately, there is an option to utilize a GPU for both indexing and querying.
| Method | Device | Indexing Time | Querying Time (1000) | F1 Score |
| FAISS IVF Index | CPU | 1.92 s | 16 sec | 0.91 |
| GPU | 1.80 s | 88.2 ms | 0.91 |
By using a GPU, the query time improved dramatically from 16 seconds to 88.2 ms, while maintaining a superior score compared to all other methods we explored. However, similar to Elasticsearch, FAISS has its own set of advantages and disadvantages. For instance, noise in the strings—such as additional words, irrelevant values, or numbers—can lead to poor-quality vectors, resulting in suboptimal matches for queries.
For example, “Product One” and “Product One Pro” produce different vectors.
Haystack
Haystack is an excellent platform for designing question-answer search systems. It employs several algorithms, including FAISS and Elasticsearch, to find answers based on context. Haystack features built-in query pipelines that enhance query processing and the quality of results. As a framework, it requires the construction of an index and a database for storing information. However, since our use case primarily involves searching for identifiers, utilizing individual algorithms where parameter tuning is straightforward may be a more effective choice.
Let’s overlook the performance of each algorithm we tried till now –


Can we go beyond?
At this point, we have identified two top-performing algorithms: ElasticSearch and FAISS. One utilizes keyword matching, while the other employs a vectorized approach to match the vectors of strings. Each method has its own strengths and weaknesses. Both algorithms demonstrate impressive F1 scores and query evaluation times. To leverage the strengths of both methods, we decided to integrate them. The basic idea is to retrieve results from FAISS and then pass those results to ElasticSearch for re-ranking. The following flow diagram illustrates this process.
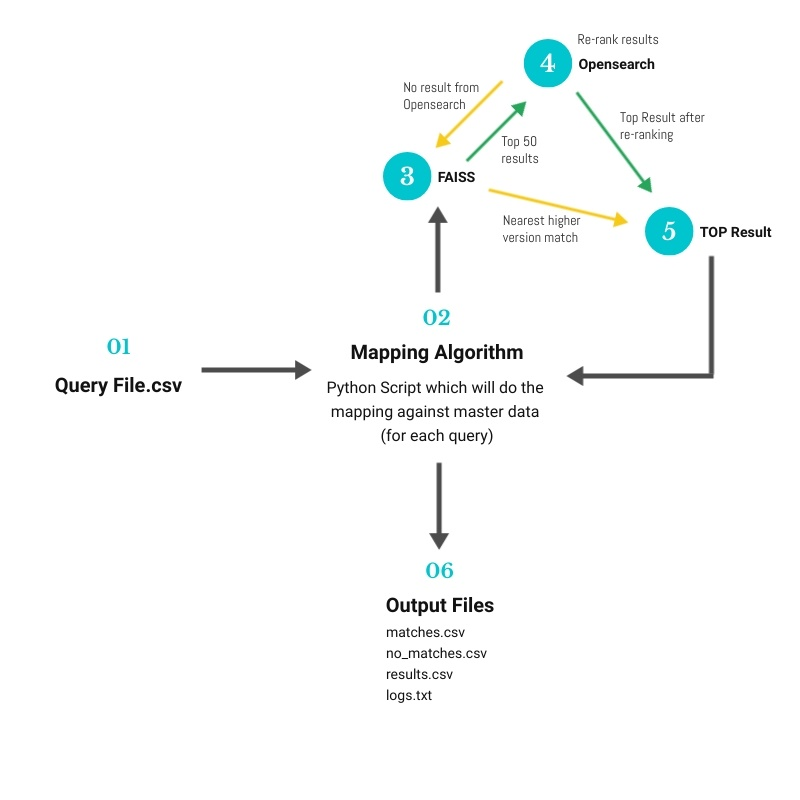
As demonstrated, the accuracy has improved by leveraging the strengths of both algorithms.
Final Thoughts
We explored a variety of methods and algorithms for conducting similarity searches, utilizing both keyword-based approaches and vector-based search techniques. Ultimately, we chose to integrate ElasticSearch and FAISS to achieve optimal performance and results.